云服务器服务器运维实战:如何高效处理多个客户端连接?
1 服务器简介
服务器是提供计算服务的设备。高性能Linux服务器运维。由于服务器需要响应用户请求,因此在处理能力、稳定性、安全性、可扩展性、可管理性等方面提出了更高的要求。随着虚拟化技术的进步,云服务器(ECS)在国内迅速普及服务器运维技术,其管理方式比物理服务器更简单、更高效。用户可以快速创建或发布任意数量的云服务器,帮助企业降低开发、运维难度和整体IT成本,让整个研发周期专注于核心业务创新。在网络环境中,根据服务器提供的服务类型不同,分为文件服务器、

本次学习总结的主要内容是高性能linux服务器的运维:
如何处理多个客户端连接。探索面对数百万客户端连接的性能优化。服务器处理并发数据的效率。深入分析大数据通信时的 Linux 内核瓶颈。如何克服瓶颈 2 I/O 多路复用技术
2.1 循环模式
当服务器有多个网络连接需要处理时,它会循环打开网络连接列表以确定是否有数据要读取。缺点:
慢(必须遍历所有网络连接)低效(可能在处理一个连接时阻塞,阻止检查和处理其他网络连接)示例:{int; ;};// std::deque ;// queue 1std::deque;// queue 2 void ::(std::deque *){char data[1024] = {0};int len = 0;for(int i = 0; i size( ); ++i){//当没有数据要读取时,发生阻塞 len = read(->at(i)., data, data); //处理数据 bzero(data, data);//清空缓存 }}
2.2 种方式
首先,将第二、三、四参数所指向的点复制到内核,轮询每个SET描述符,并记录在临时结果(fdset)中。如果发生事件,临时结果将被写入用户空间并返回。
缺点:
返回后,需要一一检查描述符是否为SET(事件是否发生)。(支持的
文件描述符数量太少,默认为1024)。
例子:
无效 ::(std::deque *){char 数据[1024] = {0}; input;// fdset 记录轮询结果 int len = 0; 整数 = 0; (&input);// 清除记录 for(int i = 0; i size(); ++i){(->at(i)., &input); = (->at(i). + 1, &input, NULL, NULL, NULL);//检测事件是否发生 if(> 0 && (->at(i)., &input)){//读取数据len = read(->at(i)., data, data);//处理数据 bzero(data, data);}//处理其他事情}}
2.3 轮询方式
与 poll 不同的是,需要注意的事件通过数组传递给内核,因此描述符的数量没有限制。和 中的字段用于表示感兴趣的事件和发生的事件,因此数组只需要初始化一次。poll的实现机制类似。它对应于内核,只是 poll 将一个数组传递给内核,然后轮询 poll 中的每个描述符。与处理 fdset 相比,poll 效率更高。
缺点:
poll 需要检查其中每个元素的值,以了解是否发生了事件。
例子:
std:: ;void ::(std::deque *){int = 0;int len = 0;char data[1024] = {0};//初始化容器 for(int i = 0; i size (); ++i){ pfd;pfd.fd = ->at(i).;//设置。= ;//设置事件 pfd. = 0;//设置无事件返回,设置为零。(pfd); }while(1){ = poll(&*.begin(), .size(), -1);//负数表示无限等待,直到有事件发生并返回for(::it = .begin(); it != .end() && > 0; ++it){ // 遍历查看fd产生的事件 if (it-> & ){len = read(it->fd, buf , data); //处理数据 bzero(data, data);}}//处理其他东西}}
相关视频推荐
linux下epoll的秘密——支撑亿级IO的底层基石
90分钟了解Linux内存架构,numa的优势,slab的实现,原理
为什么dpdk越来越火,看完让人豁然开朗
学习地址:C/C++ Linux服务器开发/后端架构师【零语音教育】-学习视频教程-腾讯课堂
C/C++ Linux服务器架构师需要学习资料和获取(资料包括C/C++、Linux、技术、Nginx、MySQL、Redis、ZK、流媒体、CDN、P2P、K8S、TCP/IP、协程、DPDK等.),免费分享
2.4 epoll方法
与 epoll 和 poll 不同的是,它不需要每次调用时都将事件描述信息复制到内核中。第一次调用后,事件信息会与对应的 epoll 描述符相关联。其次,epoll不是通过轮询,而是在等待描述符上注册一个回调函数。当事件发生时,回调函数负责将发生的事件存储到就绪事件列表中,最后写入用户空间。
epoll返回后,这个参数指向的缓冲区就是发生的事件,缓冲区中的每个元素都可以被处理,不需要像poll一样轮询和检查。
例子:
void ::(std::deque *){int ;//事件个数 int i = 0;int len = 0;char data[1024] = {0};int = (1024); //(i = 0; i size(); ++i){ ev;ev. = | ;//设置触发事件的类型 ev.data.fd = ->at(i).;//到epoll add( ( , , ->at(i)., &ev )
多线程技术还可以处理高并发客户端连接,因为可以在服务器中创建大量线程来监视连接。缺点:多线程技术不适合处理长连接,因为在linux中建立线程会消耗栈空间,并且在产生大量连接时会耗尽系统内存。例子:
{int; pid;bool ;};std::deque ;//客户端队列 void ::(){int i = 0;//创建多线程连接 for(i = 0; i , data, data); //处理数据 bzero(data, data);//清空缓存}(NULL);}
多线程+I/O多路复用技术,用一个线程监控一个端口和描述符是否有读写事件,然后将事件分发给其他工作线程处理数据。模型架构:
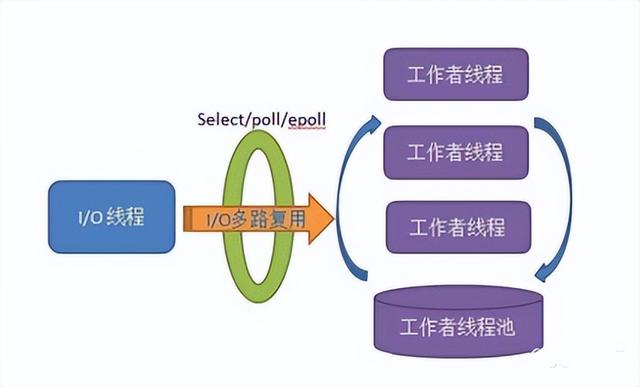
该架构主要基于单线程I/O复用(/poll/epoll),实现了高并发,避免了多线程I/O来回切换的各种开销。线程进一步提高业务处理能力,避免产生过多线程。
4 CPU多核并行计算
程序的线程是指可以同时并发执行的逻辑单元数,通过时间片分配算法实现;
CPU的线程是指使CPU的指令执行过程(取指、解释、执行、内存访问、写入数据)流水线化以提高并发性的方法。
并行计算和多线程的区别:
并行计算的 CPU 利用率比多线程高,因此相对来说效率更高。并行计算是使用多个 CPU 内核进行计算,而多线程是使用一个 CPU 内核在不同的时间段进行计算。并行计算是在多核 CPU 上运行多个线程,多线程是在单核 CPU 上运行多个线程。
综上所述,可以得出结论,多线程并不能真正提升数据处理能力,受限于单核CPU的性能。当服务器需要执行大量数据操作(如图形处理、复杂算法)时,可以考虑多核并行计算。
5 深入分析内核性能
5.1 中断处理
当大量数据包到达网络时,会产生频繁的硬件中断请求。这些硬件中断可以中断较低优先级的软中断或系统调用的执行。高性能开销。
5.2 内存拷贝
一般情况下,一个网络数据包从网卡到应用程序需要经过以下过程:数据从网卡通过DMA(直接内存访问)等方式传输到内核打开的缓冲区,以及然后从内核空间复制到用户空间。在 Linux 内核协议栈中,这个耗时的操作甚至占到整个数据包处理流程的 57.1%。
5.3 上下文切换
频繁到达的硬件中断和软中断随时可能抢占系统调用的执行,会产生大量的上下文切换开销。此外,在基于多线程的服务器设计框架中,线程间的调度也会产生频繁的上下文切换开销。同样,锁竞争的能耗也是一个很严重的问题。
5.4 本地故障
现在的主流处理器都是多核的,也就是说一个数据包的处理可能会跨越多个CPU核。例如服务器运维技术,一个数据包可能在cpu0上被中断,在cpu1上以内核态处理,在cpu2上以用户态处理。多核很容易导致CPU缓存失效和本地失效。
5.5 内存管理
传统的服务器内存页是 4K。为了提高内存访问速度,避免缓存未命中,可以增加缓存中映射表的条目,但这会影响CPU的检索效率。结合以上问题,可以看出内核本身就是一个非常大的瓶颈,解决办法就是想办法绕过内核。
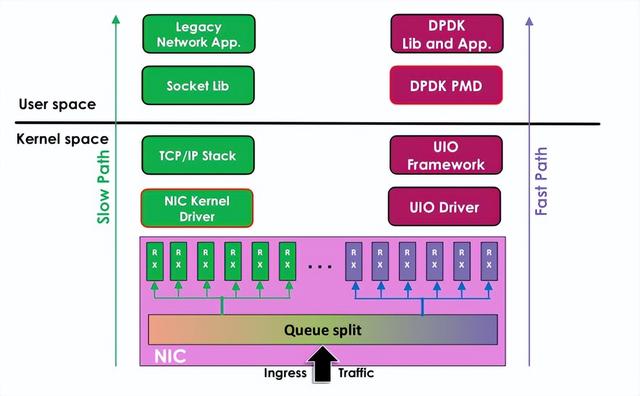
6 高性能网络框架DPDK
DPDK 提供库函数和驱动程序支持,以在 Intel 处理器架构下的用户空间中进行高效的数据包处理。它不同于为通用目的而设计的Linux系统,而是专注于对网络应用程序中的数据包进行高性能处理。
DPDK官网:
DPDK架构图:
Linux内核网络数据流:
硬件中断--->获取包分发给内核线程--->软件中断--->内核线程处理协议栈中的包--->通知用户层和用户层接收封装-->网络层--->逻辑层-->业务层
DPDK网络数据流:
硬件中断--->放弃中断过程,用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
一起来看看dpdk取得了哪些突破?
在UIO(用户空间I/O技术)的支持下,dpdk可以绕过内核协议栈,这本质上要归功于UIO技术。UIO可以拦截中断并重置中断回调行为,从而绕过后续的内核协议栈。工艺流程。
本站为粉丝站,提供全网最新优惠码和最全优惠券。本站优惠码只能在中文站使用,香港主机、艺术主机、美国VPS均可使用。
不同时间段,官方会给渠道不同的优惠,优惠30%~70%,祝你好运!!
如果您有任何问题,请加入我们的粉丝群。
马上去中文官网选择合适的虚拟主机,活动期间还赠送1个国际域名!!

 售前咨询专员
售前咨询专员
